A new wave of Chinese frontier models — DeepSeek V3.1, Qwen 3, Moonshot Kimi K2, Zhipu GLM-4.6 — is reshaping enterprise LLM economics in 2026. Why the future is multi-model, and the architecture Malaysian enterprises should adopt now.
For two years the conversation about frontier AI orbited the same three names: OpenAI, Anthropic, Google. In 2026 that conversation has changed shape.
DeepSeek V3.1, Alibaba's Qwen 3, Moonshot's Kimi K2, Zhipu's GLM-4.6, ByteDance's Doubao — Chinese frontier labs are now appearing at or near the top of public benchmarks for coding, reasoning and agent execution. They are not "alternatives" to the US flagships anymore. For specific workload classes, they are the better choice — and for many enterprises in our region, the only choice that scales at the volumes the business actually needs.
This post is what we are telling Malaysian customers: the LLM race is no longer unipolar, the right strategy is no longer to standardise on a single vendor, and the architecture decisions you make in 2026 should be designed around model portability from day one.
The shift nobody can ignore
The first phase of the LLM race was a contest of raw intelligence. Whoever shipped the smartest model won the headlines.
The next phase is different. The questions that decide which models actually get deployed at scale are:
- Who delivers intelligence at the lowest unit cost?
- Who can be deployed inside our regulatory boundary?
- Who supports tools, agents and orchestration the best?
- Who has the developer ecosystem we can hire from?
- Who is open enough to run on our own infrastructure if we need it to be?
That is no longer just model competition. It is ecosystem competition — and the field is now genuinely global.
Where the Chinese frontier is gaining ground
1. Cost-performance is becoming disruptive
The biggest single shift is unit economics. Several Chinese frontier models now deliver close-to-flagship reasoning and coding capability at a small fraction of the cost-per-token of GPT-5.5 or Claude Opus 4.7.
That matters because enterprise AI does not scale on benchmarks. It scales on monthly invoices. When a workload routes hundreds of millions of tokens per month, the gap between premium-tier flagship pricing and budget-tier Chinese-model pricing is what decides whether the project is profitable or not. We covered the underlying token economics in our LLM tokens deep-dive — that piece is the prerequisite reading for this one.
For workloads where 90–95% of premium model performance is acceptable, the right choice is rarely the most expensive model. It is whichever model gives that 90–95% with sustainable economics.

2. Open-weight momentum is changing how enterprises build
This may be the more important story. The strongest Chinese frontier labs ship open-weight or semi-open-weight models — DeepSeek V3.1, Qwen 3, GLM-4.6 — at a cadence US frontier labs simply cannot match.
For enterprises this enables four things in 2026 that were difficult or impossible in 2024:
- Self-hosted deployment inside your own infrastructure, including Malaysian data-residency boundaries.
- Lower-cost RAG and orchestration stacks because you stop paying per-token for high-volume internal workloads.
- More controllable agents where the model weights, system prompts and audit logs are all under one roof.
- Better enterprise sovereignty when the procurement, security or legal team needs evidence that customer data never leaves your perimeter.
The conversation has shifted from which model is smartest? to which model can I actually build products with, on the infrastructure I control? That is a meaningfully different question.
3. Coding and agent workloads are moving fast
The strongest momentum from Chinese frontier labs in 2025–2026 has been on coding and agentic execution — tool calling, planning, multi-step reasoning, the things that matter for production agents rather than chat-only use cases.
DeepSeek V3.1 and Kimi K2 in particular have delivered competitive results on agentic coding benchmarks against Claude Opus and GPT. For enterprises building agents (we mapped the framework landscape in our agent SDK comparison), this means model choice for the agent layer is no longer a one-vendor decision.
Where Western frontier models still lead
Let us be honest with the comparison.
OpenAI, Anthropic and Google still hold material advantages in 2026:
- Enterprise trust and governance maturity. US frontier labs have spent years building the trust scaffolding — SOC 2 reports, data-handling commitments, model cards, safety evaluations — that risk-averse buyers in regulated sectors require.
- Multimodal depth. Gemini 3.1 Pro's Video-MME lead is the largest single benchmark gap in any flagship category right now (covered in our flagship comparison).
- Ecosystem integration. Microsoft 365 + Azure OpenAI, Google Workspace + Vertex, and Anthropic's MCP ecosystem are deeper, more polished, and more globally available than anything coming out of China today.
- Production-grade reliability. SLAs, regional availability, support response times — all still meaningfully better on the Western incumbents.
This is not a replacement story. It is a market broadening story. The enterprise that runs nothing but Chinese models in 2026 is making just as narrow a bet as the enterprise that runs nothing but OpenAI.
The real battle is ecosystem against ecosystem
The most important shift for buyers is that the unit of competition is no longer the model itself. Winning is now about owning the best stack:
- The model layer.
- The agent SDK and orchestration framework.
- The developer tooling.
- The open-weight ecosystem (or lack of one).
- The cloud distribution.
- The hardware partnership story.
That is a much bigger game than "who has the best benchmark this quarter." And it is much harder to dominate. The likely outcome is not one winner — it is two or three regional ecosystems that all reach maturity, with overlap in the middle.
Why the future is multi-model
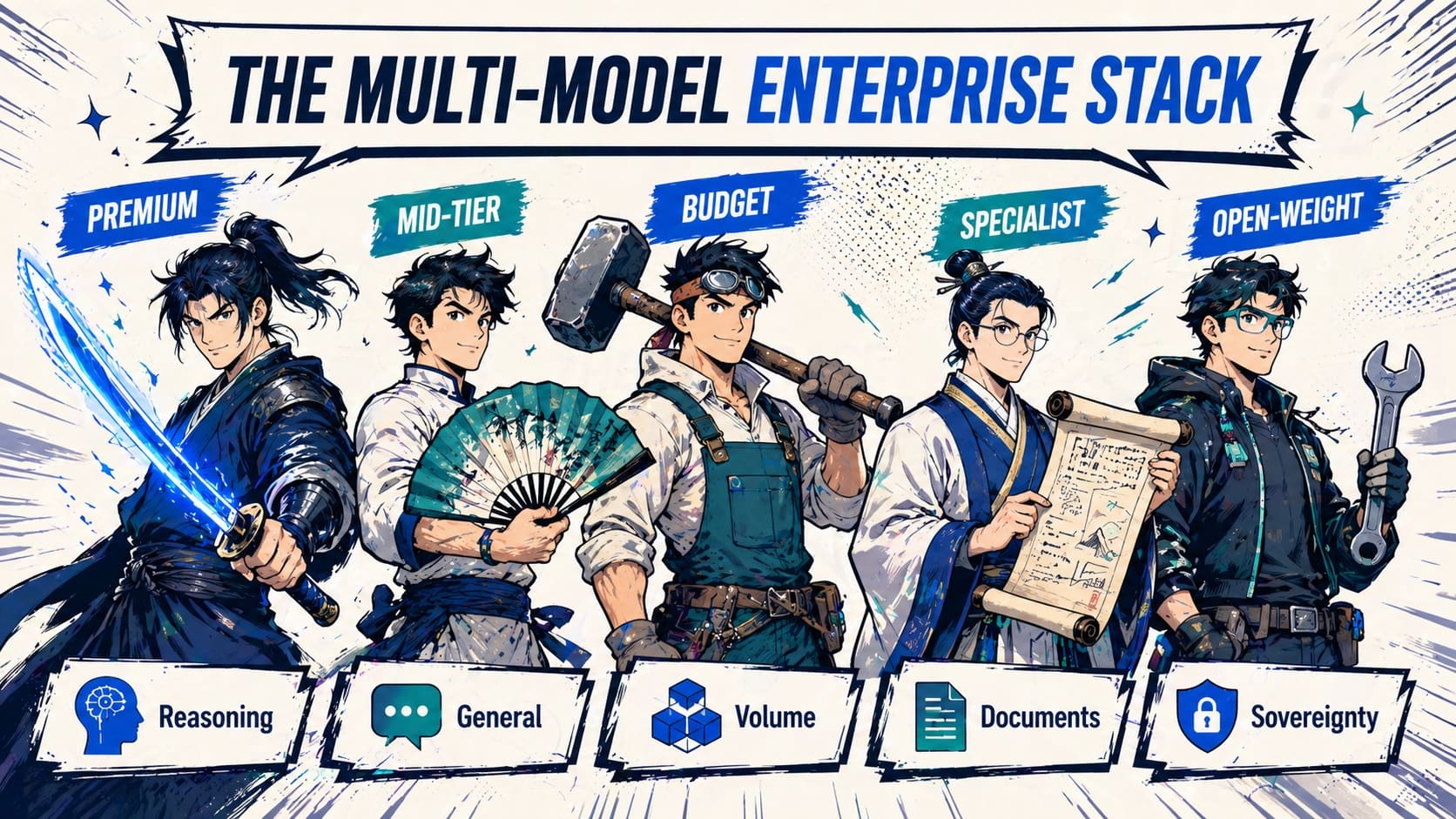
After two years building agentic AI for Malaysian banks, insurers, fintechs and shared-services centres, we no longer recommend that any enterprise standardise on one model vendor. Production deployments increasingly look like portfolios:
- A premium flagship for the workloads where reasoning quality is non-negotiable — credit underwriting, regulatory drafting, complex code generation.
- A mid-tier model for general enterprise reasoning — content generation, summarisation, customer-facing chat.
- A budget or open-weight model for high-volume back-office workloads — classification, extraction, internal RAG, batch enrichment.
- A specialised model for specific tasks — Gemini for documents and video, DeepSeek for coding agents, Qwen 3 for Mandarin and multilingual customer interactions.
- A self-hosted open-weight model for any data that cannot leave the country boundary under PDPA or BNM RMiT.
The enterprise that designs its AI stack to run that portfolio fluidly — through clean abstraction, intelligent routing, and a unified evaluation harness — is the one that captures the cost upside without losing the quality upside.
The enterprise that locks in to a single vendor is the one that pays premium pricing for budget workloads, and waits for that vendor's slowest region to catch up to the latest model release before they can use it.
The Symprio playbook for Malaysian enterprises
Five practical principles we apply to every production LLM workload we ship:
- Design for switchable models. Every prompt, every tool, every retrieval pipeline should run unchanged across at least two models. Build the abstraction once; sleep better forever.
- Route, do not standardise. A small classifier (often the budget model itself) decides which tier handles each query. A 30-line router cuts most enterprise LLM bills by 50–80% with no measurable loss in answer quality.
- Treat data residency as a routing variable, not an afterthought. For BNM RMiT or PDPA-aligned workloads, "which model" is partly a function of "where is this prompt allowed to go." Open-weight Chinese models running on Malaysian infrastructure solve a class of problems no US-hosted flagship can.
- Adopt MCP and other open protocols. Model Context Protocol is becoming the de-facto tool integration standard. A toolset built once on MCP works across Claude, GPT, Gemini, DeepSeek, Qwen and others — frameworks come and go, the protocol stays.
- Run the evaluation harness on every model. Benchmarks are marketing. Your data is reality. Score every candidate model on your real prompts, real documents and real edge cases before any procurement decision.
Three predictions for late 2026
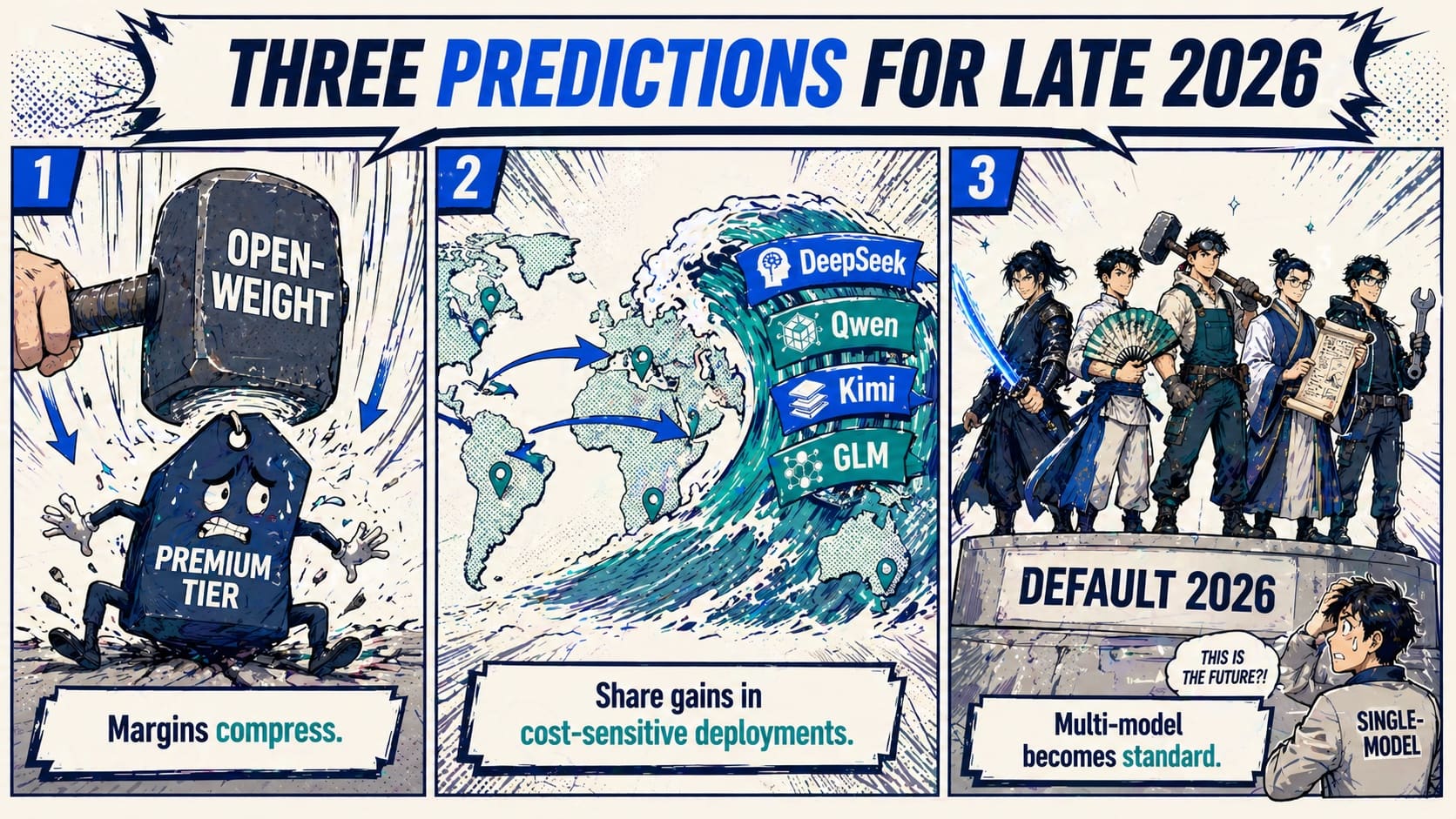
1. Open-weight pressure compresses premium model margins. The same way open-source databases reset the price floor for Oracle in the 2010s, open-weight frontier models reset the price floor for OpenAI / Anthropic / Google in the late 2020s. The premium tier still exists; it just stops being where most tokens flow.
2. Chinese frontier models gain meaningful share in cost-sensitive deployments. Especially in developer-heavy workloads (code generation, agent tool calling) and high-volume back-office workloads where premium pricing was the actual blocker.
3. Multi-model architectures become the default. Single-model dependence becomes a procurement red flag — the same way single-cloud dependence became one in 2020. Risk teams start asking the question.
Final thought
The biggest disruption in 2026 may not be a single model that beats GPT or Claude.
It may be the realisation that there is no longer one race — there are several, each with different winners, all of them reachable from one well-designed enterprise stack.
The LLM race is no longer unipolar. It is multipolar now. And the enterprises that design for that reality will compound advantage on the ones that do not.
Symprio designs, builds and operates multi-model AI stacks for Malaysian enterprises across banking, insurance, fintech and shared services. Explore our Agentic AI practice or book a 30-minute architecture session.